
تعتبر مستندات PDF جزءًا أساسيًا من العديد من العمليات التجارية، وغالبًا ما تتطلب الوصول البرمجي إلى محتواها الممسوح ضوئيًا. يمكن أن يكون استخراج النص من ملفات PDF الممسوحة ضوئيًا معقدًا، مما يجعل الأدوات الفعالة ضرورية. في هذا الدليل، سوف نستكشف كيفية استخدام OCR لمستندات PDF واستخراج النص من PDF في C# باستخدام Aspose.OCR لواجهة برمجة التطبيقات .NET، وهي مكتبة رائدة لاستخراج نص PDF متاحة للتقييم المجاني.
ما الذي ستتعلمه
في هذه المقالة، سنغطي الموضوعات التالية:
- نظرة عامة على Aspose.OCR لواجهة برمجة التطبيقات .NET
- خطوات استخدام OCR لمستند PDF واستخراج النص
- كيفية إجراء OCR على PDF وحفظ النص
- تحويل OCR PDF إلى Word
- تحويل OCR PDF إلى JSON
نظرة عامة على Aspose.OCR لواجهة برمجة التطبيقات .NET
سنستخدم Aspose.OCR لواجهة برمجة التطبيقات .NET، وهي حل قوي لـ PDF OCR يعتمد على .NET Core. تم تصميم هذه الواجهة بشكل خاص للتعرف على النص من الصور الممسوحة ضوئيًا، وصور الهواتف الذكية، ولقطات الشاشة، مع إرجاع النتائج بتنسيقات مستندات مختلفة. لا تقوم فقط بتحويل الصور إلى نص، بل تنشئ أيضًا ملفات PDF قابلة للبحث من المسحات وتصحيح أي أخطاء إملائية في النص المعترف به، مما يجعلها واحدة من أسرع حلول OCR PDF في C# المتاحة مقابل 99 دولارًا فقط.
تتميز الواجهة بفئة AsposeOcr التي تقدم عدة طرق لعمليات OCR. ومن الجدير بالذكر أن طريقة RecognizePdf(string, DocumentRecognitionSettings) أساسية لاستخراج النص من مستند PDF محدد. تسمح لك فئة DocumentRecognitionSettings بتخصيص عملية التعرف، بينما encapsulates فئة RecognitionResult نتائج التعرف.
يمكنك تنزيل DLL للواجهة أو تثبيتها عبر NuGet:
PM> Install-Package Aspose.OCR
خطوات استخدام OCR لمستند PDF واستخراج النص في C#
لإجراء OCR على مستندات PDF واستخراج النص المعترف به، اتبع الخطوات التالية:
- أنشئ مثيلاً من فئة AsposeOcr.
- قم بتهيئة كائن من فئة DocumentRecognitionSettings.
- حدد اللغة لـ OCR.
- احصل على RecognitionResult من خلال استدعاء طريقة RecognizePdf()، مع تمرير مسار الصورة وكائن DocumentRecognitionSettings.
- قم بالتكرار عبر قائمة RecognitionResult لعرض النص المحدد.
إليك مثال يوضح كيفية استخدام OCR لمستندات PDF واستخراج النص المعترف به في C#:
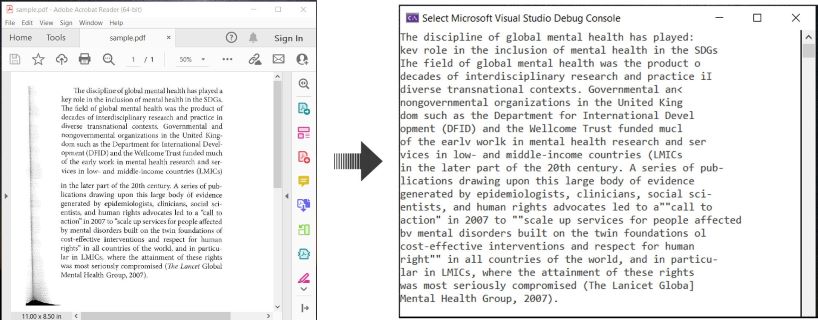
OCR PDF و استخراج النص من PDF في C#
كيفية إجراء OCR على PDF وحفظ النص في C#
لإجراء OCR على مستندات PDF وحفظ النص المعترف به، اتبع الخطوات التالية:
- أنشئ مثيلاً من فئة AsposeOcr.
- قم بتهيئة كائن من فئة DocumentRecognitionSettings.
- حدد اللغة لـ OCR.
- استدعِ طريقة RecognizePdf() للحصول على RecognitionResult.
- احفظ النص باستخدام طريقة SaveMultipageDocument()، التي تتطلب مسار الملف الناتج، وSaveFormat، وكائن RecognitionResult.
إليك مثال يوضح كيفية استخدام OCR لمستندات PDF وحفظ النص المعترف به في C#:
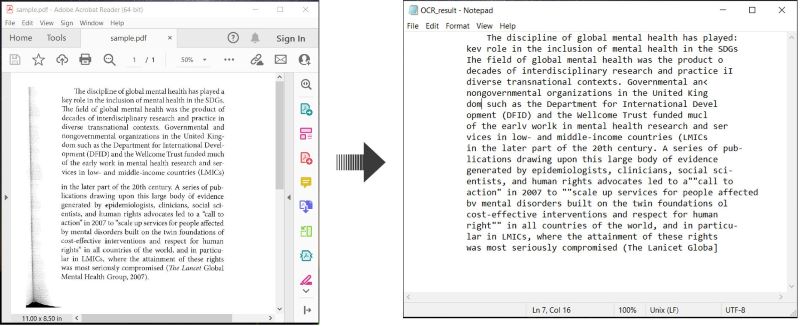
إجراء OCR على PDF وحفظ النص في C#
تحويل OCR PDF إلى Word في C#
لتحويل مستندات PDF الممسوحة ضوئيًا إلى Word، اتبع نفس الخطوات الموضحة سابقًا، ولكن حدد SaveFormat.Docx في الخطوة النهائية.
إليك مثال يوضح كيفية استخدام OCR لمستند PDF وحفظ النص المعترف به كوثيقة Word في C#:
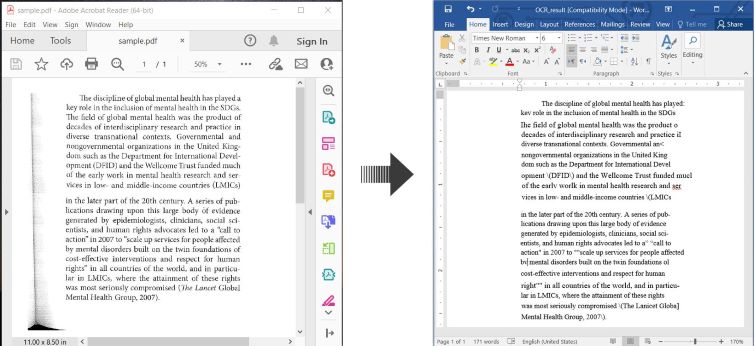
OCR PDF و تحويل مستند PDF الممسوح ضوئيًا إلى Word في C#
تحويل OCR PDF إلى JSON في C#
لحفظ النص المعترف به من مستندات PDF في ملف JSON، اتبع الخطوات السابقة مع تغيير واحد فقط وهو تحديد SaveFormat.Json في الخطوة النهائية.
إليك مثال يوضح كيفية استخدام OCR لمستند PDF وحفظ النص المعترف به كملف JSON في C#:
الحصول على ترخيص تقييم مجاني
يمكنك الحصول على ترخيص مؤقت مجاني لتقييم Aspose.OCR لواجهة برمجة التطبيقات .NET دون أي قيود.
الخاتمة
في هذا الدليل، تعلمنا كيفية إجراء OCR على مستندات PDF واستخراج النص من PDF في C#. كما استكشفنا كيفية حفظ النص المعترف به كملف TXT، وDOCX، وJSON. لمزيد من المعلومات حول Aspose.OCR لواجهة برمجة التطبيقات .NET، تحقق من التوثيق. إذا كان لديك أي أسئلة، لا تتردد في التواصل معنا عبر المنتدى.