
PDF-Dokumente spielen eine entscheidende Rolle in vielen Geschäftsprozessen und erfordern oft programmgesteuerten Zugriff auf ihren gescannten Inhalt. Das Extrahieren von Text aus gescannten PDF-Dateien kann komplex sein, weshalb effektive Werkzeuge unerlässlich sind. In diesem Tutorial werden wir erforschen, wie man PDF-Dokumente OCR und Text aus PDF in C# extrahiert, mit der leistungsstarken Aspose.OCR für .NET API, einer führenden C# PDF Text Extraktionsbibliothek, die für eine kostenlose Evaluierung verfügbar ist.
Was Sie Lernen Werden
In diesem Artikel werden wir die folgenden Themen behandeln:
- Überblick über Aspose.OCR für .NET API
- Schritte zur OCR PDF und Text extrahieren
- Wie man OCR auf PDF durchführt und Text speichert
- OCR PDF in Word konvertieren
- OCR PDF in JSON konvertieren
Überblick über Aspose.OCR für .NET API
Wir werden die Aspose.OCR für .NET API nutzen, eine robuste .NET Core PDF OCR Lösung. Diese API ist speziell dafür ausgelegt, Text aus gescannten Bildern, Smartphone-Fotos und Screenshots zu erkennen und Ergebnisse in verschiedenen Dokumentformaten zurückzugeben. Sie wandelt nicht nur Bilder in Text um, sondern erstellt auch durchsuchbare PDFs aus Scans und korrigiert Rechtschreibfehler im erkannten Text, was sie zu einer der schnellsten C# PDF OCR Lösungen macht, die für nur 99 $ erhältlich ist.
Die API bietet die AsposeOcr Klasse, die mehrere Methoden für OCR-Operationen bietet. Besonders wichtig ist die RecognizePdf(string, DocumentRecognitionSettings) Methode, die entscheidend für das Extrahieren von Text aus einem bestimmten PDF-Dokument ist. Die DocumentRecognitionSettings Klasse ermöglicht es Ihnen, den Erkennungsprozess anzupassen, während die RecognitionResult Klasse die Ergebnisse der Erkennung kapselt.
Sie können die DLL der API herunterladen oder sie über NuGet installieren:
PM> Install-Package Aspose.OCR
Schritte zur OCR PDF und Text extrahieren in C#
Um OCR auf PDF-Dokumenten durchzuführen und den erkannten Text zu extrahieren, befolgen Sie diese Schritte:
- Erstellen Sie eine Instanz der AsposeOcr Klasse.
- Initialisieren Sie ein Objekt der DocumentRecognitionSettings Klasse.
- Geben Sie die Sprache für die OCR an.
- Erhalten Sie das RecognitionResult, indem Sie die RecognizePdf() Methode aufrufen und den Pfad zum Bild sowie das DocumentRecognitionSettings Objekt übergeben.
- Durchlaufen Sie die RecognitionResult Liste, um den identifizierten Text anzuzeigen.
Hier ist ein Beispiel, das zeigt, wie man PDF-Dokumente OCR und den erkannten Text in C# extrahiert:
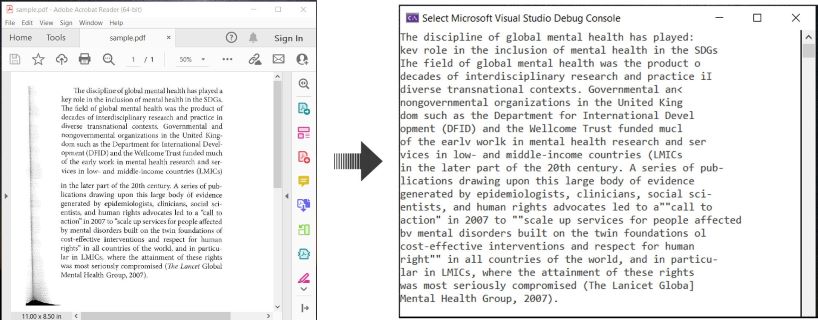
OCR PDF und Text aus PDF in C# extrahieren
Wie man OCR auf PDF durchführt und Text in C# speichert
Um OCR auf PDF-Dokumenten durchzuführen und den erkannten Text zu speichern, befolgen Sie diese Schritte:
- Erstellen Sie eine Instanz der AsposeOcr Klasse.
- Initialisieren Sie ein Objekt der DocumentRecognitionSettings Klasse.
- Geben Sie die Sprache für die OCR an.
- Rufen Sie die RecognizePdf() Methode auf, um das RecognitionResult zu erhalten.
- Speichern Sie den Text mit der SaveMultipageDocument() Methode, die den Ausgabepfad, das SaveFormat und das RecognitionResult Objekt erfordert.
Hier ist ein Beispiel, das zeigt, wie man PDF-Dokumente OCR und den erkannten Text in C# speichert:
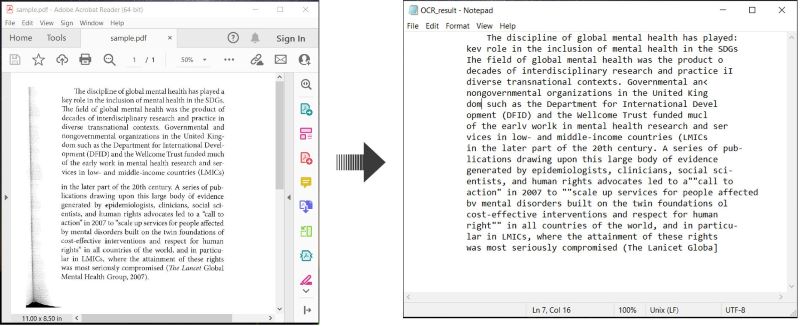
OCR auf PDF durchführen und Text in C# speichern
OCR PDF in Word konvertieren in C#
Um gescannte PDF-Dokumente in Word zu konvertieren, befolgen Sie die gleichen Schritte wie zuvor, geben Sie jedoch SaveFormat.Docx im letzten Schritt an.
Hier ist ein Beispiel, das zeigt, wie man PDF OCR und den erkannten Text als Word-Dokument in C# speichert:
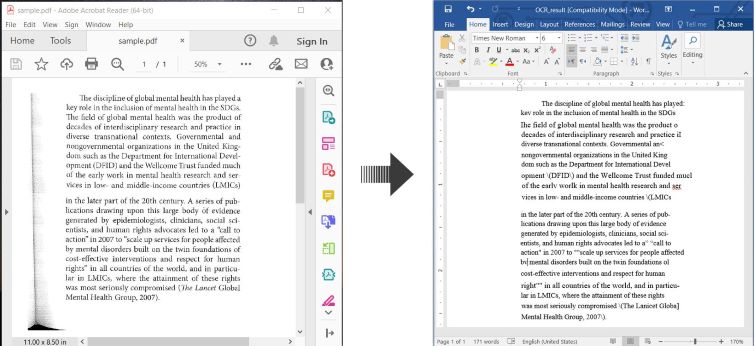
OCR PDF und gescanntes PDF in Word konvertieren in C#
OCR PDF in JSON konvertieren in C#
Um den erkannten Text aus PDF-Dokumenten in einer JSON-Datei zu speichern, befolgen Sie die vorherigen Schritte, wobei die einzige Änderung darin besteht, SaveFormat.Json im letzten Schritt anzugeben.
Hier ist ein Beispiel, das zeigt, wie man PDF OCR und den erkannten Text als JSON-Datei in C# speichert:
Holen Sie sich eine kostenlose Evaluierungslizenz
Sie können eine kostenlose temporäre Lizenz erhalten, um die Aspose.OCR für .NET API ohne Einschränkungen zu evaluieren.
Fazit
In diesem Tutorial haben wir gelernt, wie man OCR auf PDF-Dokumenten durchführt und Text aus PDF in C# extrahiert. Wir haben auch erkundet, wie man den erkannten Text als TXT, DOCX und JSON Datei speichert. Weitere Informationen zur Aspose.OCR für .NET API finden Sie in der Dokumentation. Wenn Sie Fragen haben, zögern Sie nicht, uns in unserem Forum zu kontaktieren.