
Los documentos PDF juegan un papel crucial en muchos procesos empresariales, a menudo requiriendo acceso programático a su contenido escaneado. Extraer texto de archivos PDF escaneados puede ser complejo, lo que hace que las herramientas efectivas sean esenciales. En este tutorial, exploraremos cómo realizar OCR en documentos PDF y extraer texto de PDF en C# utilizando el potente Aspose.OCR para .NET API, una biblioteca líder de extracción de texto PDF en C# disponible para evaluación gratuita.
Lo Que Aprenderá
En este artículo, cubriremos los siguientes temas:
- Descripción general de Aspose.OCR para .NET API
- Pasos para OCR PDF y Extraer Texto
- Cómo Realizar OCR en PDF y Guardar Texto
- Convertir OCR PDF a Word
- Convertir OCR PDF a JSON
Descripción General de Aspose.OCR para .NET API
Utilizaremos el Aspose.OCR para .NET API, una robusta solución OCR PDF para .NET Core. Esta API está diseñada específicamente para reconocer texto de imágenes escaneadas, fotos de teléfonos inteligentes y capturas de pantalla, devolviendo resultados en varios formatos de documento. No solo convierte imágenes a texto, sino que también crea PDFs buscables a partir de escaneos y corrige cualquier error ortográfico en el texto reconocido, lo que la convierte en una de las soluciones OCR PDF en C# más rápidas disponibles por solo $99.
La API cuenta con la clase AsposeOcr, que ofrece múltiples métodos para operaciones OCR. Notablemente, el método RecognizePdf(string, DocumentRecognitionSettings) es esencial para extraer texto de un documento PDF especificado. La clase DocumentRecognitionSettings le permite personalizar el proceso de reconocimiento, mientras que la clase RecognitionResult encapsula los resultados del reconocimiento.
Puede descargar el DLL de la API o instalarlo a través de NuGet:
PM> Install-Package Aspose.OCR
Pasos para OCR PDF y Extraer Texto en C#
Para realizar OCR en documentos PDF y extraer el texto reconocido, siga estos pasos:
- Cree una instancia de la clase AsposeOcr.
- Inicialice un objeto de la clase DocumentRecognitionSettings.
- Especifique el idioma para OCR.
- Obtenga el RecognitionResult invocando el método RecognizePdf(), pasando la ruta de la imagen y el objeto DocumentRecognitionSettings.
- Recorra la lista de RecognitionResult para mostrar el texto identificado.
Aquí hay un ejemplo que ilustra cómo realizar OCR en documentos PDF y extraer texto reconocido en C#:
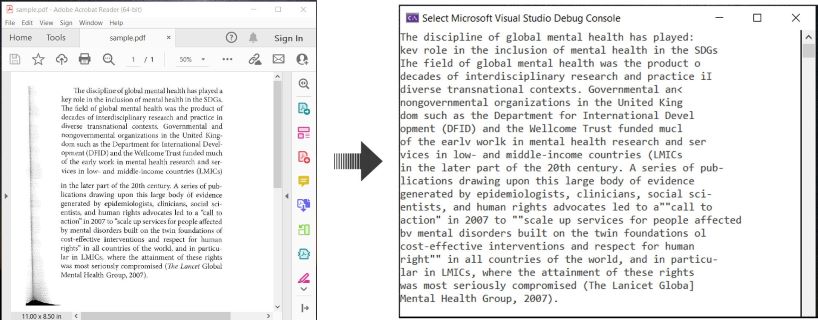
OCR PDF y Extraer Texto de PDF en C#
Cómo Realizar OCR en PDF y Guardar Texto en C#
Para realizar OCR en documentos PDF y guardar el texto reconocido, siga estos pasos:
- Cree una instancia de la clase AsposeOcr.
- Inicialice un objeto de la clase DocumentRecognitionSettings.
- Especifique el idioma para OCR.
- Llame al método RecognizePdf() para obtener el RecognitionResult.
- Guarde el texto utilizando el método SaveMultipageDocument(), que requiere la ruta del archivo de salida, el SaveFormat y el objeto RecognitionResult.
Aquí hay un ejemplo que demuestra cómo realizar OCR en documentos PDF y guardar el texto reconocido en C#:
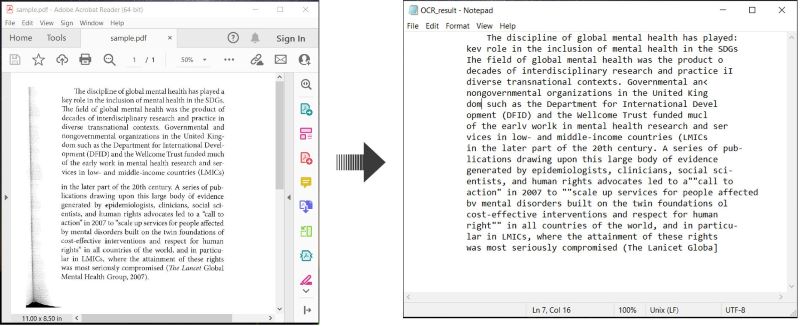
Realizar OCR en PDF y Guardar Texto en C#
Convertir OCR PDF a Word en C#
Para convertir documentos PDF escaneados a Word, siga los mismos pasos que se describieron anteriormente, pero especifique SaveFormat.Docx en el paso final.
Aquí hay un ejemplo que ilustra cómo realizar OCR en PDF y guardar el texto reconocido como un documento de Word en C#:
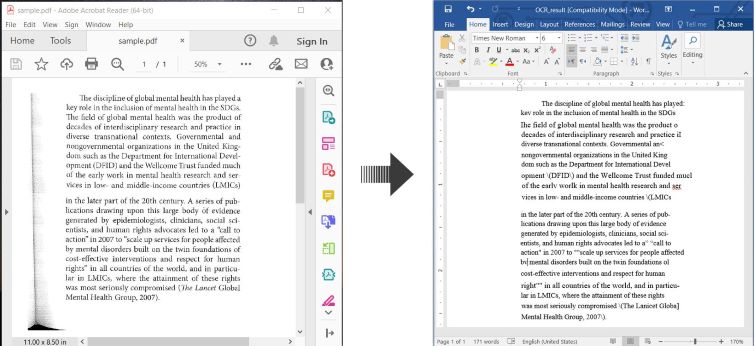
OCR PDF y Convertir PDF Escaneado a Word en C#
Convertir OCR PDF a JSON en C#
Para guardar el texto reconocido de documentos PDF en un archivo JSON, siga los pasos anteriores con el único cambio de especificar SaveFormat.Json en el paso final.
Aquí hay un ejemplo que demuestra cómo realizar OCR en PDF y guardar el texto reconocido como un archivo JSON en C#:
Obtenga una Licencia de Evaluación Gratuita
Puede obtener una licencia temporal gratuita para evaluar el Aspose.OCR para .NET API sin ninguna limitación.
Conclusión
En este tutorial, aprendimos cómo realizar OCR en documentos PDF y extraer texto de PDF en C#. También exploramos cómo guardar el texto reconocido como un archivo TXT, DOCX, y JSON. Para obtener más información sobre el Aspose.OCR para .NET API, consulte su documentación. Si tiene alguna pregunta, no dude en comunicarse con nosotros en nuestro foro.