
PDF文書は多くのビジネスプロセスに不可欠であり、スキャンされたコンテンツにプログラム的にアクセスする必要があります。スキャンされたPDFファイルからテキストを抽出することは複雑であり、効果的なツールが不可欠です。このチュートリアルでは、強力なAspose.OCR for .NET APIを使用して、C#でPDF文書をOCR処理し、PDFからテキストを抽出する方法を探ります。このAPIは、無料で評価できるC# PDFテキスト抽出ライブラリのリーディングです。
学べること
この記事では、以下のトピックをカバーします:
- Aspose.OCR for .NET APIの概要
- PDFをOCR処理してテキストを抽出する手順
- PDFでOCRを実行し、テキストを保存する方法
- OCR PDFをWordに変換する
- OCR PDFをJSONに変換する
Aspose.OCR for .NET APIの概要
私たちは、堅牢な.NET Core PDF OCRソリューションであるAspose.OCR for .NET APIを利用します。このAPIは、スキャンされた画像、スマートフォンの写真、スクリーンショットからテキストを認識するために特別に設計されており、さまざまな文書形式で結果を返します。画像をテキストに変換するだけでなく、スキャンから検索可能なPDFを作成し、認識されたテキストのスペルミスを修正することもできるため、$99で入手可能な最も高速なC# PDF OCRソリューションの1つです。
APIには、OCR操作のための複数のメソッドを提供するAsposeOcrクラスがあります。特に、指定されたPDF文書からテキストを抽出するために不可欠なRecognizePdf(string, DocumentRecognitionSettings)メソッドがあります。DocumentRecognitionSettingsクラスを使用すると、認識プロセスをカスタマイズできます。一方、RecognitionResultクラスは、認識の結果をカプセル化します。
APIのDLLをダウンロードするか、NuGetを介してインストールできます:
PM> Install-Package Aspose.OCR
C#でPDFをOCR処理してテキストを抽出する手順
PDF文書にOCRを実行し、認識されたテキストを抽出するには、次の手順に従います:
- AsposeOcrクラスのインスタンスを作成します。
- DocumentRecognitionSettingsクラスのオブジェクトを初期化します。
- OCRの言語を指定します。
- RecognizePdf()メソッドを呼び出してRecognitionResultを取得し、画像パスとDocumentRecognitionSettingsオブジェクトを渡します。
- RecognitionResultリストをループして、識別されたテキストを表示します。
以下は、C#でPDF文書をOCR処理し、認識されたテキストを抽出する方法を示す例です:
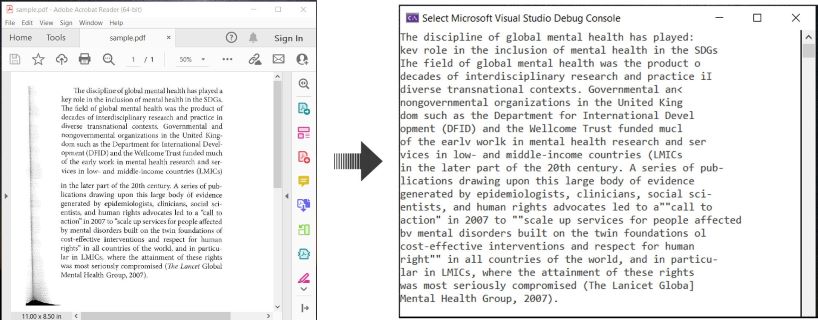
C#でのOCR PDFとPDFからのテキスト抽出
PDFでOCRを実行し、テキストを保存する方法
PDF文書にOCRを実行し、認識されたテキストを保存するには、次の手順に従います:
- AsposeOcrクラスのインスタンスを作成します。
- DocumentRecognitionSettingsクラスのオブジェクトを初期化します。
- OCRの言語を指定します。
- RecognizePdf()メソッドを呼び出してRecognitionResultを取得します。
- **SaveMultipageDocument()**メソッドを使用してテキストを保存します。このメソッドには、出力ファイルパス、SaveFormat、およびRecognitionResultオブジェクトが必要です。
以下は、C#でPDF文書をOCR処理し、認識されたテキストを保存する方法を示す例です:
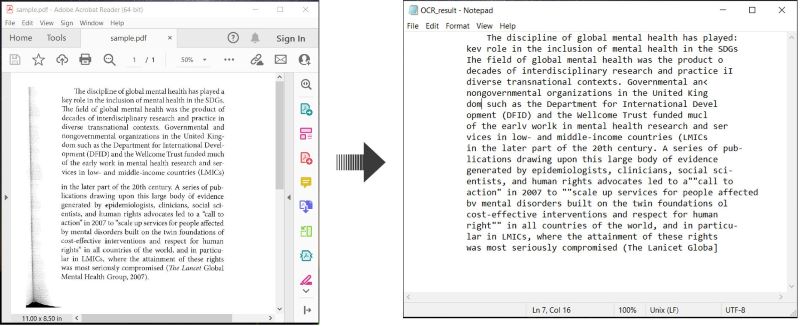
C#でのPDFにOCRを実行し、テキストを保存する
C#でOCR PDFをWordに変換する
スキャンされたPDF文書をWordに変換するには、前述の手順に従い、最終ステップでSaveFormat.Docxを指定します。
以下は、C#でOCR PDFを処理し、認識されたテキストをWord文書として保存する方法を示す例です:
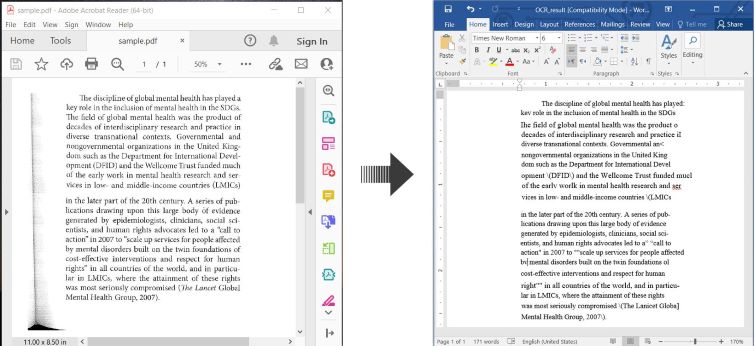
C#でのOCR PDFとスキャンされたPDFをWordに変換する
C#でOCR PDFをJSONに変換する
PDF文書から認識されたテキストをJSONファイルに保存するには、前述の手順に従い、最終ステップでSaveFormat.Jsonを指定します。
以下は、C#でOCR PDFを処理し、認識されたテキストをJSONファイルとして保存する方法を示す例です:
無料評価ライセンスを取得
Aspose.OCR for .NET APIを制限なしで評価するための無料の一時ライセンスを取得できます。
結論
このチュートリアルでは、PDF文書にOCRを実行し、C#でPDFからテキストを抽出する方法を学びました。また、認識されたテキストをTXT、DOCX、およびJSONファイルとして保存する方法も探りました。Aspose.OCR for .NET APIに関する詳細は、そのドキュメントを確認してください。質問がある場合は、フォーラムでお気軽にお問い合わせください。