
เอกสาร PDF เป็นส่วนสำคัญของกระบวนการทางธุรกิจหลายอย่าง มักจะต้องการการเข้าถึงเนื้อหาที่สแกนทางโปรแกรม การดึงข้อความจากไฟล์ PDF ที่สแกนสามารถซับซ้อน ทำให้เครื่องมือที่มีประสิทธิภาพเป็นสิ่งจำเป็น ในบทแนะนำนี้ เราจะสำรวจ วิธีการ OCR เอกสาร PDF และดึงข้อความจาก PDF ใน C# โดยใช้ Aspose.OCR สำหรับ .NET API ซึ่งเป็นห้องสมุดการดึงข้อความจาก PDF ใน C# ที่มีชื่อเสียงและสามารถประเมินได้ฟรี
สิ่งที่คุณจะได้เรียนรู้
ในบทความนี้ เราจะครอบคลุมหัวข้อต่อไปนี้:
- ภาพรวมของ Aspose.OCR สำหรับ .NET API
- ขั้นตอนในการ OCR PDF และดึงข้อความ
- วิธีการทำ OCR บน PDF และบันทึกข้อความ
- การแปลง OCR PDF เป็น Word
- การแปลง OCR PDF เป็น JSON
ภาพรวมของ Aspose.OCR สำหรับ .NET API
เราจะใช้ Aspose.OCR สำหรับ .NET API ซึ่งเป็นโซลูชัน PDF OCR ที่แข็งแกร่งใน .NET Core API นี้ถูกออกแบบมาโดยเฉพาะเพื่อจดจำข้อความจากภาพที่สแกน รูปภาพจากสมาร์ทโฟน และภาพหน้าจอ โดยส่งคืนผลลัพธ์ในรูปแบบเอกสารต่าง ๆ มันไม่เพียงแค่แปลงภาพเป็นข้อความ แต่ยังสร้าง PDF ที่ค้นหาได้จากการสแกนและแก้ไขข้อผิดพลาดในการสะกดในข้อความที่จดจำ ทำให้มันเป็นหนึ่งในโซลูชัน C# PDF OCR ที่เร็วที่สุดที่มีราคาเพียง $99
API มีคลาส AsposeOcr ซึ่งมีหลายวิธีสำหรับการดำเนินการ OCR โดยเฉพาะวิธี RecognizePdf(string, DocumentRecognitionSettings) ที่สำคัญสำหรับการดึงข้อความจากเอกสาร PDF ที่ระบุ คลาส DocumentRecognitionSettings ช่วยให้คุณปรับแต่งกระบวนการจดจำ ในขณะที่คลาส RecognitionResult จะรวมผลลัพธ์ของการจดจำ
คุณสามารถ ดาวน์โหลด DLL ของ API หรือทำการติดตั้งผ่าน NuGet:
PM> Install-Package Aspose.OCR
ขั้นตอนในการ OCR PDF และดึงข้อความใน C#
เพื่อทำ OCR บนเอกสาร PDF และดึงข้อความที่จดจำ ให้ทำตามขั้นตอนเหล่านี้:
- สร้างอินสแตนซ์ของคลาส AsposeOcr
- เริ่มต้นอ็อบเจ็กต์ของคลาส DocumentRecognitionSettings
- ระบุภาษาสำหรับ OCR
- รับ RecognitionResult โดยเรียกใช้วิธี RecognizePdf() โดยส่งพาธของภาพและอ็อบเจ็กต์ DocumentRecognitionSettings
- วนลูปผ่านรายการ RecognitionResult เพื่อแสดงข้อความที่ระบุ
นี่คือตัวอย่างที่แสดง วิธีการ OCR เอกสาร PDF และดึงข้อความที่จดจำใน C#:
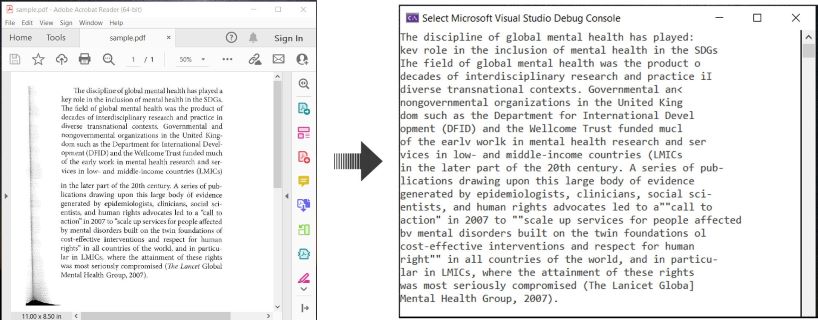
OCR PDF และดึงข้อความจาก PDF ใน C#
วิธีการทำ OCR บน PDF และบันทึกข้อความใน C#
เพื่อทำ OCR บนเอกสาร PDF และบันทึกข้อความที่จดจำ ให้ทำตามขั้นตอนเหล่านี้:
- สร้างอินสแตนซ์ของคลาส AsposeOcr
- เริ่มต้นอ็อบเจ็กต์ของคลาส DocumentRecognitionSettings
- ระบุภาษาสำหรับ OCR
- เรียกใช้วิธี RecognizePdf() เพื่อรับ RecognitionResult
- บันทึกข้อความโดยใช้วิธี SaveMultipageDocument() ซึ่งต้องการพาธไฟล์เอาท์พุท, SaveFormat และอ็อบเจ็กต์ RecognitionResult
นี่คือตัวอย่างที่แสดง วิธีการ OCR เอกสาร PDF และบันทึกข้อความที่จดจำใน C#:
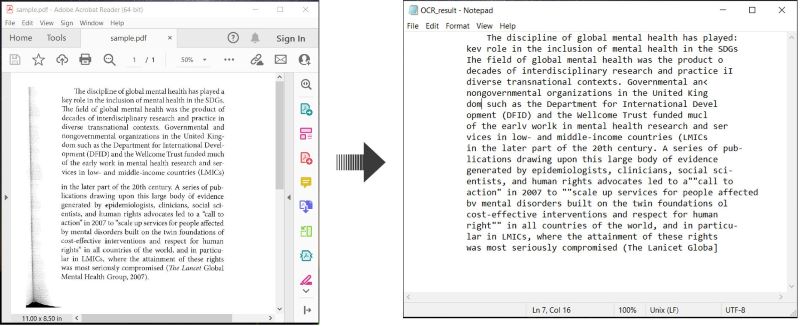
ทำ OCR บน PDF และบันทึกข้อความใน C#
การแปลง OCR PDF เป็น Word ใน C#
เพื่อแปลงเอกสาร PDF ที่สแกนเป็น Word ให้ทำตามขั้นตอนเดียวกันที่กล่าวไว้ก่อนหน้านี้ แต่ระบุ SaveFormat.Docx ในขั้นตอนสุดท้าย
นี่คือตัวอย่างที่แสดง วิธีการ OCR PDF และบันทึกข้อความที่จดจำเป็นเอกสาร Word ใน C#:
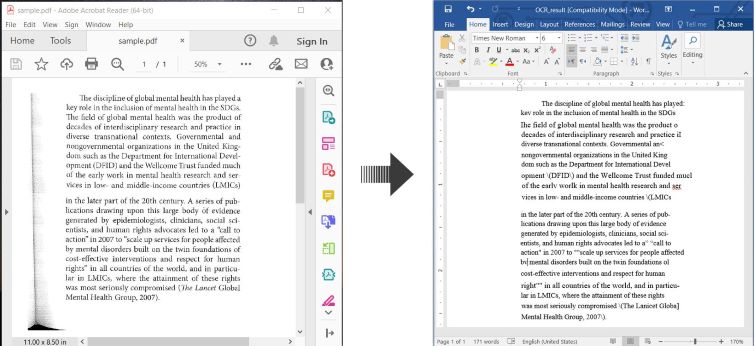
OCR PDF และแปลง PDF ที่สแกนเป็น Word ใน C#
การแปลง OCR PDF เป็น JSON ใน C#
เพื่อบันทึกข้อความที่จดจำจากเอกสาร PDF ในไฟล์ JSON ให้ทำตามขั้นตอนก่อนหน้านี้โดยมีการเปลี่ยนแปลงเพียงอย่างเดียวคือการระบุ SaveFormat.Json ในขั้นตอนสุดท้าย
นี่คือตัวอย่างที่แสดง วิธีการ OCR PDF และบันทึกข้อความที่จดจำเป็นไฟล์ JSON ใน C#:
รับใบอนุญาตการประเมินฟรี
คุณสามารถ ขอใบอนุญาตชั่วคราวฟรี เพื่อประเมิน Aspose.OCR สำหรับ .NET API โดยไม่มีข้อจำกัดใด ๆ
สรุป
ในบทแนะนำนี้ เราได้เรียนรู้วิธีการทำ OCR บนเอกสาร PDF และดึงข้อความจาก PDF ใน C# นอกจากนี้เรายังสำรวจวิธีการบันทึกข้อความที่จดจำเป็นไฟล์ TXT, DOCX, และ JSON สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ Aspose.OCR สำหรับ .NET API โปรดตรวจสอบ เอกสาร ของมัน หากคุณมีคำถามใด ๆ โปรดติดต่อเราผ่าน ฟอรัม