
PDF belgeleri birçok iş sürecinin ayrılmaz bir parçasıdır ve genellikle taranmış içeriklerine programatik erişim gerektirir. Taranmış PDF dosyalarından metin çıkarmak karmaşık olabilir, bu nedenle etkili araçlar hayati önem taşır. Bu eğitimde, güçlü Aspose.OCR for .NET API kullanarak PDF belgelerini OCR’lamak ve PDF’den metin çıkarmak için gerekli adımları keşfedeceğiz; bu, ücretsiz değerlendirme için mevcut olan önde gelen bir C# PDF metin çıkarma kütüphanesidir.
Öğrenecekleriniz
Bu makalede aşağıdaki konuları ele alacağız:
- Aspose.OCR for .NET API’ye Genel Bakış
- PDF’yi OCR’lamak ve Metin Çıkarmak için Adımlar
- PDF’de OCR Nasıl Gerçekleştirilir ve Metin Nasıl Kaydedilir
- OCR PDF’yi Word’e Dönüştürme
- OCR PDF’yi JSON’a Dönüştürme
Aspose.OCR for .NET API’ye Genel Bakış
Taranmış görüntülerden, akıllı telefon fotoğraflarından ve ekran görüntülerinden metin tanımak için özel olarak tasarlanmış, sağlam bir .NET Core PDF OCR çözümü olan Aspose.OCR for .NET API kullanacağız. Bu API, yalnızca görüntüleri metne dönüştürmekle kalmaz, aynı zamanda taramalardan arama yapılabilir PDF’ler oluşturur ve tanınan metindeki yazım hatalarını düzeltir; bu da onu yalnızca $99 karşılığında mevcut en hızlı C# PDF OCR çözümlerinden biri haline getirir.
API, OCR işlemleri için birden fazla yöntem sunan AsposeOcr sınıfını içerir. Özellikle, belirtilen bir PDF belgesinden metin çıkarmak için RecognizePdf(string, DocumentRecognitionSettings) yöntemi gereklidir. DocumentRecognitionSettings sınıfı, tanıma sürecini özelleştirmenizi sağlarken, RecognitionResult sınıfı tanıma sonuçlarını kapsüller.
API’nin DLL’sini indirin veya NuGet aracılığıyla yükleyin:
PM> Install-Package Aspose.OCR
PDF’yi OCR’lamak ve Metin Çıkarmak için Adımlar C#‘da
PDF belgelerinde OCR gerçekleştirmek ve tanınan metni çıkarmak için şu adımları izleyin:
- AsposeOcr sınıfının bir örneğini oluşturun.
- DocumentRecognitionSettings sınıfının bir nesnesini başlatın.
- OCR için dili belirtin.
- RecognizePdf() yöntemini çağırarak RecognitionResult‘ı elde edin; resim yolunu ve DocumentRecognitionSettings nesnesini geçirin.
- Tanımlanan metni görüntülemek için RecognitionResult listesini döngüye alın.
İşte PDF belgelerini OCR’lamak ve tanınan metni C#‘da çıkarmak için bir örnek:
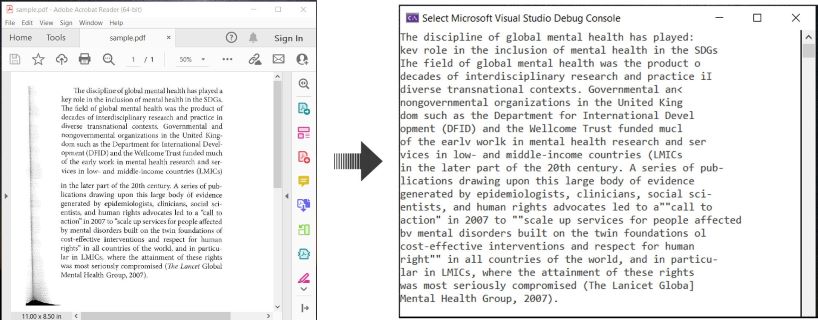
OCR PDF ve PDF’den Metin Çıkarma C#‘da
PDF’de OCR Nasıl Gerçekleştirilir ve Metin Nasıl Kaydedilir C#‘da
PDF belgelerinde OCR gerçekleştirmek ve tanınan metni kaydetmek için şu adımları izleyin:
- AsposeOcr sınıfının bir örneğini oluşturun.
- DocumentRecognitionSettings sınıfının bir nesnesini başlatın.
- OCR için dili belirtin.
- RecognitionResult‘ı elde etmek için RecognizePdf() yöntemini çağırın.
- SaveMultipageDocument() yöntemini kullanarak metni kaydedin; bu, çıktı dosyası yolunu, SaveFormat ve RecognitionResult nesnesini gerektirir.
İşte PDF belgelerini OCR’lamak ve tanınan metni C#‘da kaydetmek için bir örnek:
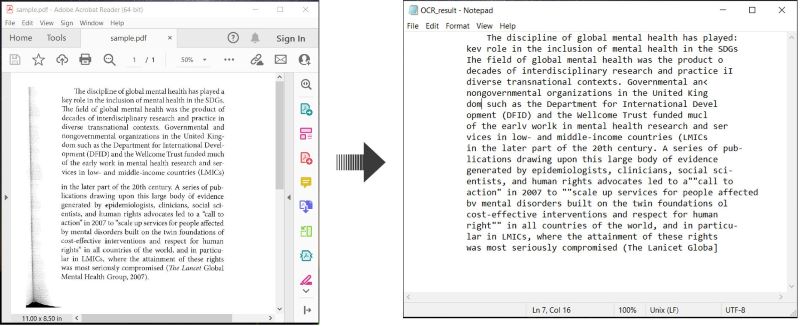
PDF’de OCR Gerçekleştir ve Metni Kaydet C#‘da
OCR PDF’yi Word’e Dönüştürme C#‘da
Taranmış PDF belgelerini Word’e dönüştürmek için daha önce belirtilen adımları izleyin, ancak son adımda SaveFormat.Docx belirtin.
İşte PDF’yi OCR’lamak ve tanınan metni C#‘da Word belgesi olarak kaydetmek için bir örnek:
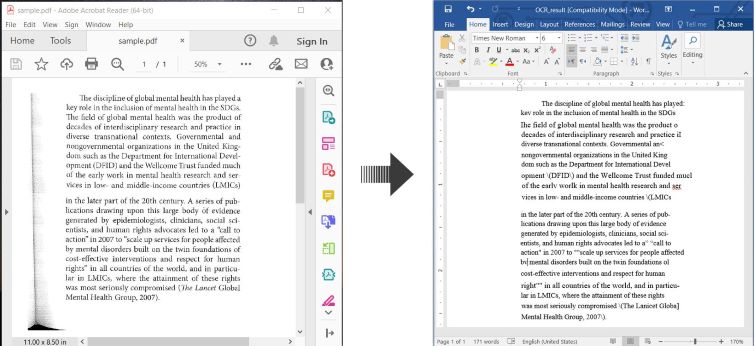
OCR PDF ve Taranmış PDF’yi C#‘da Word’e Dönüştürme
OCR PDF’yi JSON’a Dönüştürme C#‘da
PDF belgelerinden tanınan metni bir JSON dosyasında kaydetmek için önceki adımları izleyin; tek değişiklik, son adımda SaveFormat.Json belirtmektir.
İşte PDF’yi OCR’lamak ve tanınan metni C#‘da JSON dosyası olarak kaydetmek için bir örnek:
Ücretsiz Değerlendirme Lisansı Alın
Aspose.OCR for .NET API’yi sınırsız bir şekilde değerlendirmek için ücretsiz geçici bir lisans alabilirsiniz.
Sonuç
Bu eğitimde, PDF belgelerinde OCR gerçekleştirmeyi ve PDF’den metin çıkarmayı öğrendik. Ayrıca tanınan metni TXT, DOCX ve JSON dosyası olarak kaydetme yöntemlerini de keşfettik. Aspose.OCR for .NET API hakkında daha fazla bilgi için belgelere göz atın. Herhangi bir sorunuz varsa, lütfen forumumuza ulaşmaktan çekinmeyin.