
PDF-документи є невід’ємною частиною багатьох бізнес-процесів, часто вимагаючи програмного доступу до їх відсканованого вмісту. Витяг тексту з відсканованих PDF-файлів може бути складним, що робить ефективні інструменти необхідними. У цьому навчальному посібнику ми розглянемо як виконати OCR PDF-документи та витягти текст з PDF в C# за допомогою потужного Aspose.OCR для .NET API, провідної бібліотеки для витягу тексту з PDF на C#, доступної для безкоштовної оцінки.
Що ви дізнаєтеся
У цій статті ми розглянемо такі теми:
- Огляд Aspose.OCR для .NET API
- Кроки для OCR PDF та витягу тексту
- Як виконати OCR на PDF та зберегти текст
- Конвертація OCR PDF в Word
- Конвертація OCR PDF в JSON
Огляд Aspose.OCR для .NET API
Ми будемо використовувати Aspose.OCR для .NET API, надійне рішення для OCR PDF на .NET Core. Цей API спеціально розроблений для розпізнавання тексту з відсканованих зображень, фотографій зі смартфонів та скріншотів, повертаючи результати у різних форматах документів. Він не лише перетворює зображення на текст, але й створює пошукові PDF з відсканованих документів та виправляє будь-які орфографічні помилки в розпізнаному тексті, що робить його одним з найшвидших рішень для OCR PDF на C# всього за 99 доларів.
API містить клас AsposeOcr, який пропонує кілька методів для операцій OCR. Особливо важливим є метод RecognizePdf(string, DocumentRecognitionSettings) для витягу тексту з вказаного PDF-документа. Клас DocumentRecognitionSettings дозволяє налаштувати процес розпізнавання, тоді як клас RecognitionResult інкапсулює результати розпізнавання.
Ви можете завантажити DLL API або встановити його через NuGet:
PM> Install-Package Aspose.OCR
Кроки для OCR PDF та витягу тексту в C#
Щоб виконати OCR на PDF-документах і витягти розпізнаний текст, виконайте ці кроки:
- Створіть екземпляр класу AsposeOcr.
- Ініціалізуйте об’єкт класу DocumentRecognitionSettings.
- Вкажіть мову для OCR.
- Отримайте RecognitionResult, викликавши метод RecognizePdf(), передавши шлях до зображення та об’єкт DocumentRecognitionSettings.
- Пройдіть через список RecognitionResult, щоб відобразити виявлений текст.
Ось приклад, що ілюструє як виконати OCR на PDF-документах та витягти розпізнаний текст у C#:
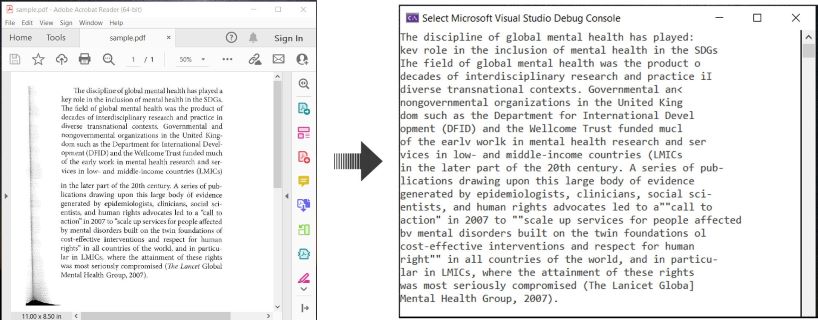
OCR PDF та витяг тексту з PDF в C#
Як виконати OCR на PDF та зберегти текст в C#
Щоб виконати OCR на PDF-документах і зберегти розпізнаний текст, виконайте ці кроки:
- Створіть екземпляр класу AsposeOcr.
- Ініціалізуйте об’єкт класу DocumentRecognitionSettings.
- Вкажіть мову для OCR.
- Викликайте метод RecognizePdf(), щоб отримати RecognitionResult.
- Збережіть текст, використовуючи метод SaveMultipageDocument(), який вимагає шлях до вихідного файлу, SaveFormat та об’єкт RecognitionResult.
Ось приклад, що демонструє як виконати OCR на PDF-документах та зберегти розпізнаний текст у C#:
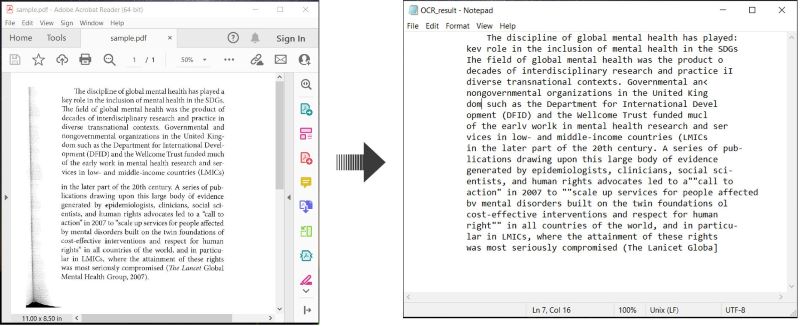
Виконати OCR на PDF та зберегти текст в C#
Конвертація OCR PDF в Word в C#
Щоб конвертувати відскановані PDF-документи в Word, виконайте ті ж кроки, що й раніше, але вкажіть SaveFormat.Docx на останньому кроці.
Ось приклад, що ілюструє як виконати OCR PDF та зберегти розпізнаний текст як документ Word у C#:
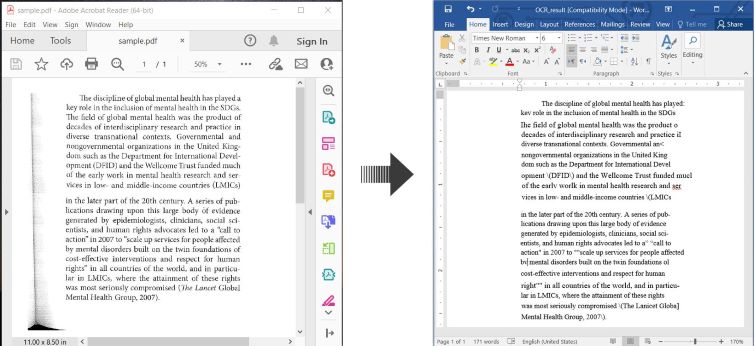
OCR PDF та конвертувати відсканований PDF в Word в C#
Конвертація OCR PDF в JSON в C#
Щоб зберегти розпізнаний текст з PDF-документів у файлі JSON, виконайте попередні кроки з єдиною зміною: вкажіть SaveFormat.Json на останньому кроці.
Ось приклад, що демонструє як виконати OCR PDF та зберегти розпізнаний текст як файл JSON у C#:
Отримати безкоштовну ліцензію для оцінки
Ви можете отримати безкоштовну тимчасову ліцензію для оцінки Aspose.OCR для .NET API без будь-яких обмежень.
Висновок
У цьому навчальному посібнику ми дізналися, як виконати OCR на PDF-документах і витягти текст з PDF в C#. Ми також розглянули, як зберегти розпізнаний текст у файлі TXT, DOCX та JSON. Для отримання додаткової інформації про Aspose.OCR для .NET API, ознайомтеся з його документацією. Якщо у вас є будь-які запитання, не соромтеся звертатися до нас на нашому форумі.